原理解读
Fisher线性判别:由Fisher于1936年提出,是一种经典的线性学习方法,其根据方差分析的思想建立起来的一种线性判别法,该判别方法对总体的分布不做任何要求。
核心思想
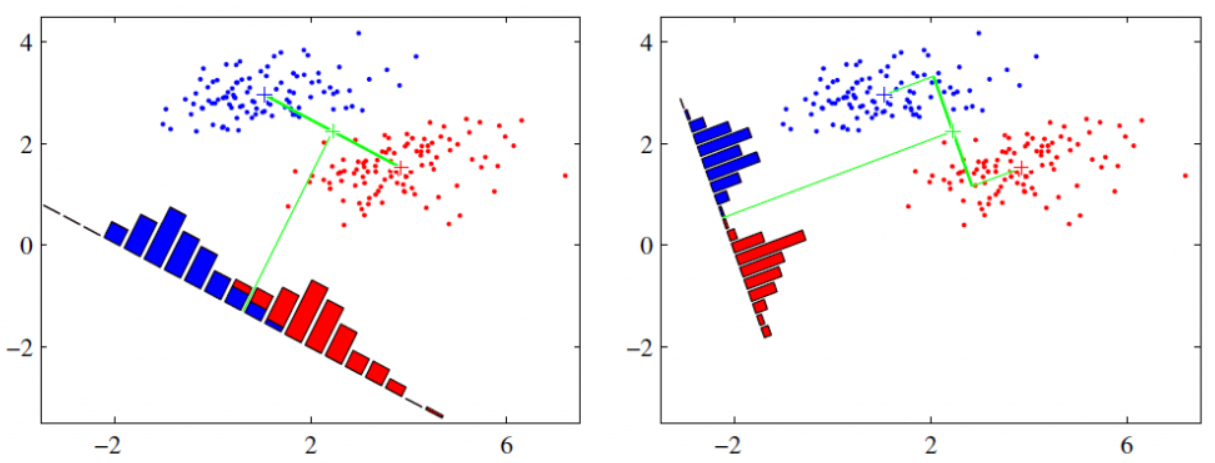
核心思想非常朴素,用周志华老师的话就是:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近,异类样例的投影点尽可能远离。在对新样本进行分类时,将其投影到同样的这条直线上,根据投影点的位置来确定新样本的类别。
设$\mu_i, \Sigma_i, i \in {0, 1}$分别表示第i类样本的均值向量和协方差矩阵。
设投影直线的表达式为$y = \omega x$,则将样本点投影到直线上,两类样本的投影中心分别为$\omega^T \mu_0, \omega^T \mu_0$,两类样本的协方差分别为$\omega^T \Sigma_0 \omega, \omega^T \Sigma_1 \omega$
为了寻找一个最优的投影直线,因此我们要尽量使得类内距离越小越好,类间距离越大越好。可以认为是一种高内聚,低耦合的思想。
要使同类样例投影点的协方差尽可能小,即$\omega^T \Sigma_0 \omega + \omega^T \Sigma_1 \omega$尽可能小,要使不同样例投影中心的距离尽可能大,即$||\omega^T \mu_0 - \omega^T \mu_1||_2^2$尽可能大。
因此得到了我们的目标函数
$$ \begin{align} J & = \frac{||\omega^T \mu_0 - \omega^T \mu_1||_2^2}{\omega^T \Sigma_0 \omega + \omega^T \Sigma_1 \omega} \ & = \frac{\omega^T (\mu_0 - \mu_1)(\mu_0 - \mu_1)^T \omega}{\omega^T (\Sigma_0 + \Sigma_1) \omega} \end{align}$$
我们定义类内散度矩阵
$$ S_{\omega} = \Sigma_0 + \Sigma_1 = \sum_{x \in X_0}(x - \mu_0)(x - \mu_0)^T + \sum_{x \in X_1}(x - \mu_1)(x - \mu_1)^T $$
我们定义类间散度矩阵
$$ S_b = (\mu_0 - \mu_1)(\mu_0 - \mu_1)^T $$
则目标函数可以重写为
$$ J = \frac{\omega^T S_b \omega}{\omega^T S_{\omega} \omega}$$
求解过程
因为分子和分母都是关于$\omega$的二次项,因此解与$\omega$的长度无关,仅仅与其方向有关,也就是说,若$\omega$是这个问题的一个解,那么对于任意常数$\alpha$,有$\alpha \omega$也是这个问题的解。因此令$\omega^T S_{\omega} \omega = 1$,则目标函数等价于
$$\underset{\omega}{argmin} \ -\omega^T S_b \omega, \ s.t. \ \omega^T S_{\omega} \omega = 1$$
使用拉格朗日乘子法可求得
$$S_b \omega = \lambda S_{\omega} \omega$$
因为$S_b \omega = (\mu_0 - \mu_1)(\mu_0 - \mu_1)^T \omega, \ (\mu_0 - \mu_1)^T \omega$是标量,因此可以设
$$S_b \omega = \lambda (\mu_0 - \mu_1)$$
综合上面两个式子可以得到
$$\omega = S_{\omega}^{-1}(\mu_0 - \mu_1)$$
代码实战
FISHER_train.m
1 | clear;clc;close all; |
FISHER_test.m
1 | close all; |
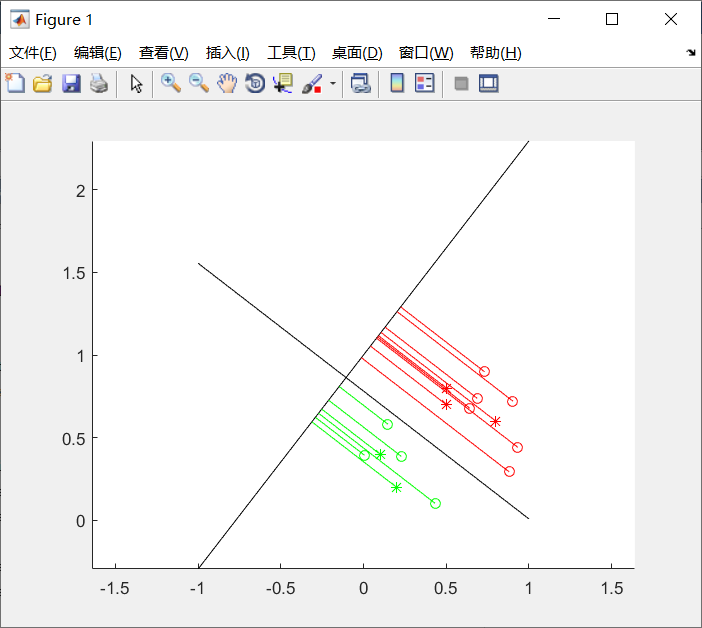
实验结果
Fisher优缺点
- 优点:
- 无需参数估计,无需训练。
- 算法简单,易于理解和实现。
- 计算量小,能够达到实时的效率。
- 缺点:
- 对于多分类问题,实现起来较为复杂。
- 样本不平衡时,尤其是一类样本多,其他类样本少时会产生严重的问题。